https://leetcode.com/problems/couples-holding-hands/
 graph 0
graph 0
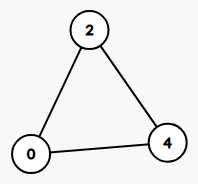 graph 1
graph 1
X. Union Find
https://leetcode.com/problems/couples-holding-hands/discuss/117520/Java-union-find-easy-to-understand-5-ms
X.
https://leetcode.com/problems/couples-holding-hands/discuss/113359/Java-AC-O(n)-greedy-solution.
N couples sit in 2N seats arranged in a row and want to hold hands. We want to know the minimum number of swaps so that every couple is sitting side by side. A swap consists of choosing any two people, then they stand up and switch seats.
The people and seats are represented by an integer from
0 to 2N-1, the couples are numbered in order, the first couple being (0, 1), the second couple being (2, 3), and so on with the last couple being (2N-2, 2N-1).
The couples' initial seating is given by
row[i] being the value of the person who is initially sitting in the i-th seat.
Example 1:
Input: row = [0, 2, 1, 3] Output: 1 Explanation: We only need to swap the second (row[1]) and third (row[2]) person.
Example 2:
Input: row = [3, 2, 0, 1] Output: 0 Explanation: All couples are already seated side by side.
Note:
len(row)is even and in the range of[4, 60].rowis guaranteed to be a permutation of0...len(row)-1
We first assign groups to elements in the array.
For example, given array
[2, 1, 5, 0, 3, 4], we assign groups as the following:[0, 1]: group0[2, 3]: group2[4, 5]: group4
To get the group number for a given array element, we can use
arr[i] & (~0x1).
As a result, if we represent
[2, 1, 5, 0, 3, 4] in group labels, we get [2, 0, 4, 0, 2, 4].
We visualize each group as a vertax of a undirected graph.
The initial connection of these vertaxes are determined by the pairs in the given array.
For example, if the array is
[0, 0, 2, 2, 4, 4], we get the following graph:graph 0
If the array is
[2, 0, 4, 0, 2, 4], we get:graph 1
Assume the size of the input array is
N, If all the couples are seat next to each other, we want the graph to have exactly N / 2connected components as shown in the [0, 0, 2, 2, 4, 4] graph.
After we convert the input array into an undirected graph, we convert the problem to:
Given this undirected graph with (N / 2) vertices, and at most two edges for a vertex, what is the minimum swaps needed to convert this graph to a graph that has exactly (N / 2) connected components?
We can observe that, for the given kind of graph, every swap is guaranteed to break one vertex free if it is in a connected component, and thus, increase the total number of connected component by
1.
For example, for the array
[2, 0, 4, 0, 2, 4], after we swap idx 0 with idx 3, we get [0, 0, 4, 2, 2, 4]. By doing this, we break vertex 0 free, and increase the connected component count from 1 to 2.
As a result, we can conclude that
(the # of components we increased) == (the # of swaps we have to do)
Our gaol is to increase the total number of components to
N / 2. Thus we have (origional # of components) + (# of components we have to increase) == N / 2.
As a result, we have:
(# of swaps we have to do) == (# of components we have to increase) == N / 2 - (origional # of components)
So, the problem now is converted to find
(origional # of connected components) in this undirected graph.
In order to find the origional number of connected components, we can do the following:
If we start with
N / 2 connected components, each time we find a new edge between two components, we have to reduce the number of our connected components by 1.
For example, for array
[0, 2, 2, 0, 4, 4], we should have 2 connected components: 0 - 2 and 4. If we start our component count at 3, when we see the first pair [0, 2], we know that component 0 and 2 are connected, so we reduce our component count to 2. Then, we see pair [2, 0], but since we already handled [0, 2], we don’t have to handle [2, 0]again since the graph is undirected. So, in the end, we find out that we have 2 connected components in the graph generated by [0, 2, 2, 0, 4, 4].
To achieve this, we can use Union-Find method.
We inspect one pair every time. If the two elements are not already in one group, we know that a new edge is now being added, which means we have to decrease the count of our connected components by
1. Then, we union these two groups.X. Union Find
https://leetcode.com/problems/couples-holding-hands/discuss/117520/Java-union-find-easy-to-understand-5-ms
Think about each couple as a vertex in the graph. So if there are N couples, there are N vertices. Now if in position 2i and 2i +1 there are person from couple u and couple v sitting there, that means that the permutations are going to involve u and v. So we add an edge to connect u and v. The min number of swaps = N - number of connected components. This follows directly from the theory of permutations. Any permutation can be decomposed into a composition of cyclic permutations. If the cyclic permutation involve k elements, we need k -1 swaps. You can think about each swap as reducing the size of the cyclic permutation by 1. So in the end, if the graph has k connected components, we need N - k swaps to reduce it back to N disjoint vertices.
Then there are many ways of doing this. We can use dfs for example to compute the number of connected components. The number of edges isn O(N). So this is an O(N) algorithm. We can also use union-find. I think a union-find is usually quite efficient. The following is an implementation.
private class UF { private int[] parents; public int count; UF(int n) { parents = new int[n]; for (int i = 0; i < n; i++) { parents[i] = i; } count = n; } private int find(int i) { if (parents[i] == i) { return i; } parents[i] = find(parents[i]); return parents[i]; } public void union(int i, int j) { int a = find(i); int b = find(j); if (a != b) { parents[a] = b; count--; } } } public int minSwapsCouples(int[] row) { int N = row.length/ 2; UF uf = new UF(N); for (int i = 0; i < N; i++) { int a = row[2*i]; int b = row[2*i + 1]; uf.union(a/2, b/2); } return N - uf.count; }
下面我们来看一种使用联合查找Union Find的解法。该解法对于处理群组问题时非常有效,比如岛屿数量有关的题就经常使用UF解法。核心思想是用一个root数组,每个点开始初始化为不同的值,如果两个点属于相同的组,就将其中一个点的root值赋值为另一个点的位置,这样只要是相同组里的两点,通过find函数会得到相同的值。 那么如果总共有n个数字,则共有 n/2 对儿,所以我们初始化 n/2 个群组,我们还是每次处理两个数字。每个数字除以2就是其群组号,那么属于同一组的两个数的群组号是相同的,比如2和3,其分别除以2均得到1,所以其组号均为1。那么这对解题有啥作用呢?作用忒大了,由于我们每次取的是两个数,且计算其群组号,并调用find函数,那么如果这两个数的群组号相同,那么find函数必然会返回同样的值,我们不用做什么额外动作,因为本身就是一对儿。如果两个数不是一对儿,那么其群组号必然不同,在二者没有归为一组之前,调用find函数返回的值就不同,此时我们将二者归为一组,并且cnt自减1,忘说了,cnt初始化为总群组数,即 n/2。那么最终cnt减少的个数就是交换的步数,还是用上面讲解中的例子来说明吧:
[3 1 4 0 2 5]
最开始的群组关系是:
群组0:0,1
群组1:2,3
群组2:4,5
取出前两个数字3和1,其群组号分别为1和0,带入find函数返回不同值,则此时将群组0和群组1链接起来,变成一个群组,则此时只有两个群组了,cnt自减1,变为了2。
群组0 & 1:0,1,2,3
群组2:4,5
此时取出4和0,其群组号分别为2和0,带入find函数返回不同值,则此时将群组0&1和群组2链接起来,变成一个超大群组,cnt自减1,变为了1。
群组0 & 1 & 2:0,1,2,3,4,5
此时取出最后两个数2和5,其群组号分别为1和2,因为此时都是一个大组内的了,带入find函数返回相同的值,不做任何处理。最终交换的步数就是cnt减少值,为2,参见代码如下:
int minSwapsCouples(vector<int>& row) { int res = 0, n = row.size(), cnt = n / 2; vector<int> root(n, 0); for (int i = 0; i < n; ++i) root[i] = i; for (int i = 0; i < n; i += 2) { int x = find(root, row[i] / 2); int y = find(root, row[i + 1] / 2); if (x != y) { root[x] = y; --cnt; } } return n / 2 - cnt; } int find(vector<int>& root, int i) { return (i == root[i]) ? i : find(root, root[i]); }
X.
https://leetcode.com/problems/couples-holding-hands/discuss/113359/Java-AC-O(n)-greedy-solution.
public int minSwapsCouples(int[] row) {
int n = row.length;
int[] pos = new int[n];
for (int i = 0; i < n; i++) {
pos[row[i]] = i;
}
int count = 0;
for (int i = 0; i < n; i += 2) {
int j = row[i] % 2 == 0 ? row[i] + 1 : row[i] - 1;
if (row[i + 1] != j) {
swap(row, pos, i + 1, pos[j]);
count++;
}
}
return count;
}
void swap(int[] row, int[] pos, int x, int y) {
int temp = row[x];
pos[temp] = y;
pos[row[y]] = x;
row[x] = row[y];
row[y] = temp;
}
有N个情侣和2N个座位,想让每一对情侣都能够牵手,也就是挨着坐。每次能交换任意两个人的座位,求最少需要换多少次座位。
解法1:cyclic swapping
public int minSwapsCouples(int[] row) { int res = 0, N = row.length; int[] ptn = new int[N]; int[] pos = new int[N]; for (int i = 0; i < N; i++) { ptn[i] = (i % 2 == 0 ? i + 1 : i - 1); pos[row[i]] = i; } for (int i = 0; i < N; i++) { for (int j = ptn[pos[ptn[row[i]]]]; i != j; j = ptn[pos[ptn[row[i]]]]) { swap(row, i, j); swap(pos, row[i], row[j]); res++; } } return res; } private void swap(int[] arr, int i, int j) { int t = arr[i]; arr[i] = arr[j]; arr[j] = t; }
You may have encountered problems that can be solved using cyclic swapping before (like lc41 and lc268). In this post, I will use a simplified
N integers problem to illustrate the cyclic swapping idea and then generalize it to this N couples problem.I -- N integers problem
Assume we have an integer array
row of length N, which contains integers from 0 up to N-1 but in random order. You are free to choose any two numbers and swap them. What is the minimum number of swaps needed so that we have i == row[i] for 0 <= i < N (or equivalently, to sort this integer array)?
First, to apply the cyclic swapping algorithm, we need to divide the
N indices into mutually exclusive index groups, where indices in each group form a cycle: i0 --> i1 --> ... --> ik --> i0. Here we employ the notation i --> j to indicate that we expect the element at index i to appear at index j at the end of the swapping process.
Before we dive into the procedure for building the index groups, here is a simple example to illustrate the ideas, assuming we have the following integer array and corresponding indices:
row: 2, 3, 1, 0, 5, 4
idx: 0, 1, 2, 3, 4, 5
Starting from index
0, what is the index that the element at index 0 is expected to appear? The answer is row[0], which is 2. Using the above notation, we have 0 --> 2. Then starting from index 2, what is the index that the element at index 2 is expected to appear? The answer will be row[2], which is 1, so we have 2 --> 1. We can continue in this fashion until the indices form a cycle, which indicates an index group has been found: 0 --> 2 --> 1 --> 3 --> 0. Then we choose another start index that has not been visited and repeat what we just did. This time we found another group: 4 --> 5 --> 4, after which all indices are visited so we conclude there are two index groups.
Now for an arbitrary integer array, we can take similar approaches to build the index groups. Starting from some unvisited index
i0, we compute the index i1 at which the element at i0 is expected to appear. In this case, i1 = row[i0]. We then continue from index i1 and compute the index i2 at which the element at i1 is expected to appear. Similarly we have, i2 = row[i1]. We continue in this fashion to construct a list of indices: i0 --> i1 --> i2 --> ... --> ik. Next we will show that eventually the list will repeat itself from index i0, which has two implications:- Eventually the list will repeat itself.
- It will repeat itself from index
i0, not other indices.
Proof of implication 1: Assume the list will never repeat itself. Then we can follow the above procedure to generate a list containing at least
(N + 1) distinct indices. This implies at least one index will be out of the range [0, N-1]. However, we know that each index in the list should represent a valid index into the row array. Therefore, all indices should lie in the range [0, N-1], a contradiction. So we conclude the list will eventually repeat itself.
Proof of implication 2: Assume the list will repeat itself at some index
j other than i0. Then we know there exists at least two different indices p and q such that we have p --> j and q --> j, which, according to the definition of the --> notation, implies at the end of the swapping process, we need to place two different elements at index jsimultaneously, which is impossible. So we conclude the list must repeat itself at index i0.
Next suppose we have produced two such index groups,
g1 and g2, which are not identical (there exists at least one index contained in g1 but not in g2 and at least one index contained in g2 but not in g1). We will show that all indices in g1 cannot appear in g2, and vice versa - - g1 and g2 are mutually exclusive. The proof is straightforward: if there is some index j that is common to both g1 and g2, then both g1 and g2 can be constructed by starting from index j and following the aforementioned procedure. Since each index is only dependent on its predecessor, the groups generated from the same start index will be identical to each other, contradicting the assumption. Therefore g1 and g2 will be mutually exclusive. This also implies the union of all groups will cover all the N indices exactly once.
Lastly, we will show that the minimum number of swaps needed to resolve an index group of size
k is given by k - 1. Here we define the size of a group as the number of distinct indices contained in the group, for example:- Size
1groups:0 --> 0,2 --> 2, etc. - Size
2groups:0 --> 3 --> 0,2 --> 1 --> 2, etc.
...... - Size
kgroups:0 --> 1 --> 2 --> ... --> (k-1) --> 0, etc.
And by saying "resolving a group", we mean placing the elements at each index contained in the group to their expected positions at the end of the swapping process. In this case, we want to put the element at index
i, which is row[i], to its expected position, which is row[i] again (the fact that the element itself coincides with its expected position is a result of the placement requirement row[i] == i).
The proof proceeds by using mathematical induction:
- Base case: If we have a group of size
1, what is the minimum number of swaps needed to resolve the group? First, what does it imply if a group has size1? A group of size1takes the formj --> j. From the definition of the-->notation, we know the element at indexjis expected to appear at indexjat the end of the swapping process. Since this is already the case (that is, element at indexjis already placed at indexj), we don't need to take any further actions, therefore the minimum number of swaps needed is0, which is the group size minus1. Hence the base case stands. - Induction case: Assume the minimum number of swaps needed to resolve a group of size
mis given bym - 1, where1 <= m <= k. For a group of sizek + 1, we can always use one swap to turn it into two mutually exclusive groups of sizek1andk2, respectively, such thatk1 + k2 = k + 1with1 <= k1, k2 <= k. This is done by first choosing any two different indicesiandjin the group, then swapping the elements at indexiwith that at indexj. Before swapping, the group is visualized as:... --> i --> p --> ... --> j --> q --> .... The swapping operation is equivalent to repointing indexito indexqmeanwhile repointing indexjto indexp. This is because the element originally at indexiis now at indexj, therefore the expected index for the element at indexjafter swapping will be the same as the one for the element at indexibefore swapping, which isp, so we havej --> pafter swapping. Similarly we havei --> qafter swapping. Therefore, the original group becomes two disjoint groups after swapping:... --> i --> q --> ...and... --> j --> p --> ..., where each group contains at least one index. Now by the induction assumption, the minimum number of swaps needed to resolve the above two groups are given byk1 - 1andk2 - 1, respectively. Therefore, the minimum number of swapping needed to resolve the original group of size(k + 1)is given by(k1 - 1) + (k2 - 1) + 1 = k1 + k2 - 1 = k. Hence the induction case also stands.
In conclusion, the minimum number of swaps needed to resolve the whole array can be obtained by summing up the minimum number of swaps needed to resolve each of the index groups. To resolve each index group, we are free to choose any two distinct indices in the group and swap them so as to reduce the group to two smaller disjoint groups. In practice, we can always choose a pivot index and continuously swap it with its expected index until the pivot index is the same as its expected index, meaning the entire group is resolved and all placement requirements within the group are satisfied.
The following is a sample implementation for this problem, where for each pivot index
i, the expected index j is computed by taking the value of row[i].public int miniSwapsArray(int[] row) {
int res = 0, N = row.length;
for (int i = 0; i < N; i++) {
for (int j = row[i]; i != j; j = row[i]) {
swap(row, i, j);
res++;
}
}
return res;
}
private void swap(int[] arr, int i, int j) {
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
II -- N couples problem
The
N couples problem can be solved using exactly the same idea as the N integers problem, except now we have different placement requirements: instead of i == row[i], we require i == ptn[pos[ptn[row[i]]]], where we have defined two additional arrays ptn and pos:ptn[i]denotes the partner of labeli(ican be either a seat or a person) - -ptn[i] = i + 1ifiis even;ptn[i] = i - 1ifiis odd.pos[i]denotes the index of the person with labeliin therowarray - -row[pos[i]] == i.
The meaning of
i == ptn[pos[ptn[row[i]]]] is as follows:- The person sitting at seat
ihas a labelrow[i], and we want to place him/her next to his/her partner. - So we first find the label of his/her partner, which is given by
ptn[row[i]]. - We then find the seat of his/her partner, which is given by
pos[ptn[row[i]]]. - Lastly we find the seat next to his/her partner's seat, which is given by
ptn[pos[ptn[row[i]]]].
Therefore, for each pivot index
i, its expected index j is given by ptn[pos[ptn[row[i]]]]. As long as i != j, we swap the two elements at index i and j, and continue until the placement requirement is satisfied. A minor complication here is that for each swapping operation, we need to swap both the row and pos arrays.
Here is a list of solutions for Java and C++. Both run at
O(N) time with O(N) space. Note that there are several optimizations we can do, just to name a few:- The
ptnarray can be replaced with a simple function that takes an indexiand returnsi + 1ori - 1depending on whetheriis even or odd. - We can check every other seat instead of all seats. This is because we are matching each person to his/her partners, so technically speaking there are always half of the people sitting at the right seats.
- There is an alternative way for building the index groups which goes in backward direction, that is instead of building the cycle like
i0 --> i1 --> ... --> jk --> i0, we can also build it likei0 <-- i1 <-- ... <-- ik <-- i0, wherei <-- jmeans the element at indexjis expected to appear at indexi. In this case, the pivot index will be changing along the cycle as the swapping operations are applied. The benefit is that we only need to do swapping on therowarray.
Java solution:
public int minSwapsCouples(int[] row) {
int res = 0, N = row.length;
int[] ptn = new int[N];
int[] pos = new int[N];
for (int i = 0; i < N; i++) {
ptn[i] = (i % 2 == 0 ? i + 1 : i - 1);
pos[row[i]] = i;
}
for (int i = 0; i < N; i++) {
for (int j = ptn[pos[ptn[row[i]]]]; i != j; j = ptn[pos[ptn[row[i]]]]) {
swap(row, i, j);
swap(pos, row[i], row[j]);
res++;
}
}
return res;
}
private void swap(int[] arr, int i, int j) {
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
这道题给了我们一个长度为n的数组,里面包含的数字是 [0, n-1] 范围内的数字各一个,让我们通过调换任意两个数字的位置,使得相邻的奇偶数靠在一起。因为要两两成对,所以题目限定了输入数组必须是偶数个。我们要明确的是,组成对儿的两个是从0开始,每两个一对儿的。比如0和1,2和3,像1和2就不行。而且检测的时候也是两个数两个数的检测,左右顺序无所谓,比如2和3,或者3和2都行。当我们暂时对如何用代码来解决问题没啥头绪的时候,一个很好的办法是,先手动解决问题,意思是,假设这道题不要求你写代码,就让你按照要求排好序怎么做。我们随便举个例子来说吧,比如:
[3 1 4 0 2 5]
我们如何将其重新排序呢?首先明确,我们交换数字位置的动机是要凑对儿,如果我们交换的两个数字无法组成新对儿,那么这个交换就毫无意义。来手动交换吧,我们两个两个的来看数字,前两个数是3和1,我们知道其不成对儿,数字3的老相好是2,不是1,那么怎么办呢?我们就把1和2交换位置呗。好,那么现在3和2牵手成功,度假去了,再来看后面的:
[3 2 4 0 1 5]
我们再取两数字,4和0,互不认识!4跟5有一腿儿,不是0,那么就把0和5,交换一下吧,得到:
[3 2 4 5 1 0]
好了,再取最后两个数字,1和0,两口子,不用动!前面都成对的话,最后两个数字一定成对。而且这种方法所用的交换次数一定是最少的,不要问博主怎么证明,博主也不会|||-.-~明眼人应该已经看出来了,这就是一种贪婪算法Greedy Algorithm。思路有了,代码就很容易写了,注意这里在找老伴儿时用了一个trick,一个数‘异或’上1就是其另一个位,这个不难理解,如果是偶数的话,最后位是0,‘异或’上1等于加了1,变成了可以的成对奇数。如果是奇数的话,最后位是1,‘异或’上1后变为了0,变成了可以的成对偶数。参见代码如下:
int minSwapsCouples(vector<int>& row) { int res = 0, n = row.size(); for (int i = 0; i < n; i += 2) { if (row[i + 1] == (row[i] ^ 1)) continue; ++res; for (int j = i + 1; j < n; ++j) { if (row[j] == (row[i] ^ 1)) { row[j] = row[i + 1]; row[i + 1] = row[i] ^ 1; break; } } } return res; }