SimHash: Hash-based Similarity Detection
Most hash functions are used to separate and obscure data, so that similar data hashes to very different keys. We propose to use hash functions for the opposite purpose: to detect similarities between data.
Using a hash function that hashed similar files to similar values, file similarity could be determined simply by comparing pre-sorted hash key values. The challenge is to find a similarity hash that minimizes false positives.
A standard technique in similarity detection is to map features of a file into some highdimensional space, and then use distance within this space as a measure of similarity. Unfortunately, this typically involves computing the distance between all pairs of files, which leads to O(n 2 ) similarity detection algorithms. If these file-to-vector mappings could be reduced to a one-dimensional space, then the data points could be sorted in O(n log n) time, greatly increasing detection speed.
Typically, hash functions are designed to minimize collisions (where two different inputs map to the same key value). With cryptographic hash functions, collisions should be nearly impossible, and nearly identical data should hash to very different keys.
Our similarity hash function had the opposite intent: very similar files should map to very similar, or even the same, hash key, and distance between keys should be some measure of the difference between files.
Semantics of Similarity
We decided to use binary similarity as our metric. Two files are similar if only a small percentage of their raw bit patterns are different.
SimHash operates at a very fine granularity, specifically byte or word level. We do not attempt complete coverage; we only care about the portions of the file which match our set of bit patterns.
We are focused on files which have a strong degree of similarity, ideally within 1-2% of each other.
http://www.titouangalopin.com/blog/2014-05-29-simhash
http://blog.csdn.net/al_xin/article/details/38919361
simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
Most hash functions are used to separate and obscure data, so that similar data hashes to very different keys. We propose to use hash functions for the opposite purpose: to detect similarities between data.
Using a hash function that hashed similar files to similar values, file similarity could be determined simply by comparing pre-sorted hash key values. The challenge is to find a similarity hash that minimizes false positives.
A standard technique in similarity detection is to map features of a file into some highdimensional space, and then use distance within this space as a measure of similarity. Unfortunately, this typically involves computing the distance between all pairs of files, which leads to O(n 2 ) similarity detection algorithms. If these file-to-vector mappings could be reduced to a one-dimensional space, then the data points could be sorted in O(n log n) time, greatly increasing detection speed.
Typically, hash functions are designed to minimize collisions (where two different inputs map to the same key value). With cryptographic hash functions, collisions should be nearly impossible, and nearly identical data should hash to very different keys.
Our similarity hash function had the opposite intent: very similar files should map to very similar, or even the same, hash key, and distance between keys should be some measure of the difference between files.
Semantics of Similarity
We decided to use binary similarity as our metric. Two files are similar if only a small percentage of their raw bit patterns are different.
SimHash operates at a very fine granularity, specifically byte or word level. We do not attempt complete coverage; we only care about the portions of the file which match our set of bit patterns.
We are focused on files which have a strong degree of similarity, ideally within 1-2% of each other.
http://www.titouangalopin.com/blog/2014-05-29-simhash
http://blog.csdn.net/al_xin/article/details/38919361
simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
simhash值的海明距离计算
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
百度的去重算法
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。
http://my.oschina.net/leejun2005/blog/150086
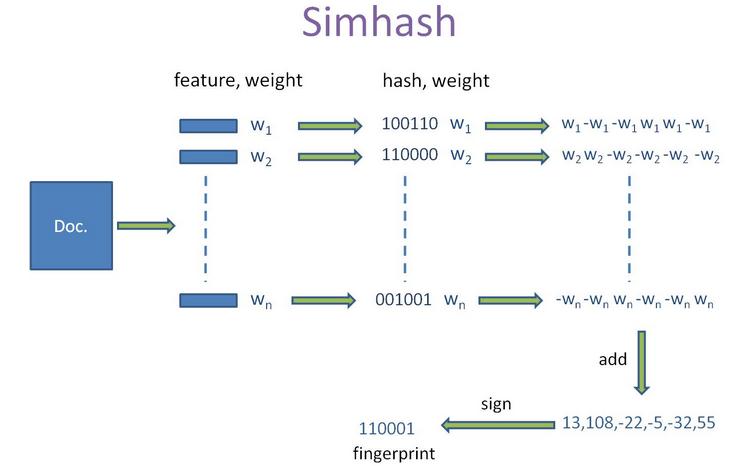
simhash算法的输入是一个向量,输出是一个 f 位的签名值。为了陈述方便,假设输入的是一个文档的特征集合,每个特征有一定的权重。比如特征可以是文档中的词,其权重可以是这个词出现的次数。 simhash 算法如下:
1,将一个 f 维的向量 V 初始化为 0 ; f 位的二进制数 S 初始化为 0 ;
2,对每一个特征:用传统的 hash 算法对该特征产生一个 f 位的签名 b 。对 i=1 到 f :
如果b 的第 i 位为 1 ,则 V 的第 i 个元素加上该特征的权重;
否则,V 的第 i 个元素减去该特征的权重。
3,如果 V 的第 i 个元素大于 0 ,则 S 的第 i 位为 1 ,否则为 0 ;
4,输出 S 作为签名。

假设对64 位的 SimHash ,我们要找海明距离在 3 以内的所有签名。我们可以把 64 位的二进制签名均分成 4块,每块 16 位。根据鸽巢原理(也成抽屉原理,见组合数学),如果两个签名的海明距离在 3 以内,它们必有一块完全相同。
我们把上面分成的4 块中的每一个块分别作为前 16 位来进行查找。 建立倒排索引。

Java Code:public class SimHash
{
private String tokens;
private BigInteger strSimHash;
private int hashbits = 128;
public SimHash(String tokens)
{
this.tokens = tokens;
this.strSimHash = this.simHash();
}
public SimHash(String tokens, int hashbits)
{
this.tokens = tokens;
this.hashbits = hashbits;
this.strSimHash = this.simHash();
}
public BigInteger simHash()
{
int[] v = new int[this.hashbits];
StringTokenizer stringTokens = new StringTokenizer(this.tokens);
while (stringTokens.hasMoreTokens())
{
String temp = stringTokens.nextToken();
BigInteger t = this.hash(temp);
for (int i = 0; i < this.hashbits; i++)
{
BigInteger bitmask = new BigInteger("1").shiftLeft(i);
if (t.and(bitmask).signum() != 0)
{
v[i] += 1;
}
else
{
v[i] -= 1;
}
}
}
BigInteger fingerprint = new BigInteger("0");
for (int i = 0; i < this.hashbits; i++)
{
if (v[i] >= 0)
{
fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i));
}
}
return fingerprint;
}
private BigInteger hash(String source)
{
if (source == null || source.length() == 0)
{
return new BigInteger("0");
}
else
{
char[] sourceArray = source.toCharArray();
BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7);
BigInteger m = new BigInteger("1000003");
BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract(
new BigInteger("1"));
for (char item : sourceArray)
{
BigInteger temp = BigInteger.valueOf((long) item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(source.length())));
if (x.equals(new BigInteger("-1")))
{
x = new BigInteger("-2");
}
return x;
}
}
public int hammingDistance(SimHash other)
{
BigInteger m = new BigInteger("1").shiftLeft(this.hashbits).subtract(
new BigInteger("1"));
BigInteger x = this.strSimHash.xor(other.strSimHash).and(m);
int tot = 0;
while (x.signum() != 0)
{
tot += 1;
x = x.and(x.subtract(new BigInteger("1")));
}
return tot;
}
public static void main(String[] args)
{
String s = "This is a test string for testing";
SimHash hash1 = new SimHash(s, 128);
System.out.println(hash1.strSimHash + " " + hash1.strSimHash.bitLength());
s = "This is a test string for testing also";
SimHash hash2 = new SimHash(s, 128);
System.out.println(hash2.strSimHash + " " + hash2.strSimHash.bitCount());
s = "This is a test string for testing als";
SimHash hash3 = new SimHash(s, 128);
System.out.println(hash3.strSimHash + " " + hash3.strSimHash.bitCount());
System.out.println("============================");
System.out.println(hash1.hammingDistance(hash2));
System.out.println(hash1.hammingDistance(hash3));
}
}
https://github.com/sing1ee/simhash-java
MinHash: http://massivealgorithms.blogspot.com/2014/12/matts-blog-minhash-for-dummies.html
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
百度的去重算法
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。
http://my.oschina.net/leejun2005/blog/150086
simhash算法的输入是一个向量,输出是一个 f 位的签名值。为了陈述方便,假设输入的是一个文档的特征集合,每个特征有一定的权重。比如特征可以是文档中的词,其权重可以是这个词出现的次数。 simhash 算法如下:
1,将一个 f 维的向量 V 初始化为 0 ; f 位的二进制数 S 初始化为 0 ;
2,对每一个特征:用传统的 hash 算法对该特征产生一个 f 位的签名 b 。对 i=1 到 f :
如果b 的第 i 位为 1 ,则 V 的第 i 个元素加上该特征的权重;
否则,V 的第 i 个元素减去该特征的权重。
3,如果 V 的第 i 个元素大于 0 ,则 S 的第 i 位为 1 ,否则为 0 ;
4,输出 S 作为签名。
假设对64 位的 SimHash ,我们要找海明距离在 3 以内的所有签名。我们可以把 64 位的二进制签名均分成 4块,每块 16 位。根据鸽巢原理(也成抽屉原理,见组合数学),如果两个签名的海明距离在 3 以内,它们必有一块完全相同。
我们把上面分成的4 块中的每一个块分别作为前 16 位来进行查找。 建立倒排索引。
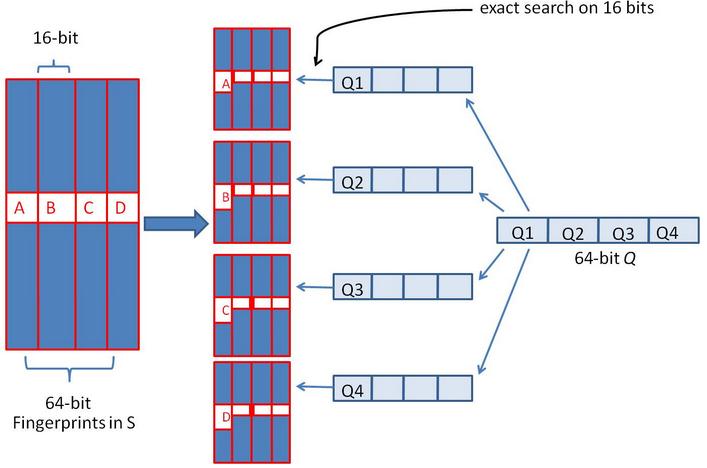
如果库中有2^34 个(大概 10 亿)签名,那么匹配上每个块的结果最多有 2^(34-16)=262144 个候选结果 (假设数据是均匀分布, 16 位的数据,产生的像限为 2^16 个,则平均每个像限分布的文档数则 2^34/2^16 = 2^(34-16)) ,四个块返回的总结果数为 4* 262144 (大概 100 万)。原本需要比较 10 亿次,经过索引,大概就只需要处理 100 万次了。由此可见,确实大大减少了计算量。
public class SimHash { private String tokens; private BigInteger intSimHash; private String strSimHash; private int hashbits = 64; public SimHash(String tokens) throws IOException { this.tokens = tokens; this.intSimHash = this.simHash(); } public SimHash(String tokens, int hashbits) throws IOException { this.tokens = tokens; this.hashbits = hashbits; this.intSimHash = this.simHash(); } HashMap<String, Integer> wordMap = new HashMap<String, Integer>(); public BigInteger simHash() throws IOException { // 定义特征向量/数组 int[] v = new int[this.hashbits]; // 英文分词 // StringTokenizer stringTokens = new StringTokenizer(this.tokens); // while (stringTokens.hasMoreTokens()) { // String temp = stringTokens.nextToken(); // } // 1、中文分词,分词器采用 IKAnalyzer3.2.8 ,仅供演示使用,新版 API 已变化。 StringReader reader = new StringReader(this.tokens); // 当为true时,分词器进行最大词长切分 IKSegmentation ik = new IKSegmentation(reader, true); Lexeme lexeme = null; String word = null; String temp = null; while ((lexeme = ik.next()) != null) { word = lexeme.getLexemeText(); // 注意停用词会被干掉 // System.out.println(word); // 2、将每一个分词hash为一组固定长度的数列.比如 64bit 的一个整数. BigInteger t = this.hash(word); for (int i = 0; i < this.hashbits; i++) { BigInteger bitmask = new BigInteger("1").shiftLeft(i); // 3、建立一个长度为64的整数数组(假设要生成64位的数字指纹,也可以是其它数字), // 对每一个分词hash后的数列进行判断,如果是1000...1,那么数组的第一位和末尾一位加1, // 中间的62位减一,也就是说,逢1加1,逢0减1.一直到把所有的分词hash数列全部判断完毕. if (t.and(bitmask).signum() != 0) { // 这里是计算整个文档的所有特征的向量和 // 这里实际使用中需要 +- 权重,比如词频,而不是简单的 +1/-1, v[i] += 1; } else { v[i] -= 1; } } } BigInteger fingerprint = new BigInteger("0"); StringBuffer simHashBuffer = new StringBuffer(); for (int i = 0; i < this.hashbits; i++) { // 4、最后对数组进行判断,大于0的记为1,小于等于0的记为0,得到一个 64bit 的数字指纹/签名. if (v[i] >= 0) { fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i)); simHashBuffer.append("1"); } else { simHashBuffer.append("0"); } } this.strSimHash = simHashBuffer.toString(); System.out.println(this.strSimHash + " length " + this.strSimHash.length()); return fingerprint; } private BigInteger hash(String source) { if (source == null || source.length() == 0) { return new BigInteger("0"); } else { char[] sourceArray = source.toCharArray(); BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7); BigInteger m = new BigInteger("1000003"); BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract(new BigInteger("1")); for (char item : sourceArray) { BigInteger temp = BigInteger.valueOf((long) item); x = x.multiply(m).xor(temp).and(mask); } x = x.xor(new BigInteger(String.valueOf(source.length()))); if (x.equals(new BigInteger("-1"))) { x = new BigInteger("-2"); } return x; } } public int hammingDistance(SimHash other) { BigInteger x = this.intSimHash.xor(other.intSimHash); int tot = 0; // 统计x中二进制位数为1的个数 // 我们想想,一个二进制数减去1,那么,从最后那个1(包括那个1)后面的数字全都反了, // 对吧,然后,n&(n-1)就相当于把后面的数字清0, // 我们看n能做多少次这样的操作就OK了。 while (x.signum() != 0) { tot += 1; x = x.and(x.subtract(new BigInteger("1"))); } return tot; } public int getDistance(String str1, String str2) { int distance; if (str1.length() != str2.length()) { distance = -1; } else { distance = 0; for (int i = 0; i < str1.length(); i++) { if (str1.charAt(i) != str2.charAt(i)) { distance++; } } } return distance; } public List subByDistance(SimHash simHash, int distance) { // 分成几组来检查 int numEach = this.hashbits / (distance + 1); List characters = new ArrayList(); StringBuffer buffer = new StringBuffer(); int k = 0; for (int i = 0; i < this.intSimHash.bitLength(); i++) { // 当且仅当设置了指定的位时,返回 true boolean sr = simHash.intSimHash.testBit(i); if (sr) { buffer.append("1"); } else { buffer.append("0"); } if ((i + 1) % numEach == 0) { // 将二进制转为BigInteger BigInteger eachValue = new BigInteger(buffer.toString(), 2); System.out.println("----" + eachValue); buffer.delete(0, buffer.length()); characters.add(eachValue); } } return characters; }}{
private String tokens;
private BigInteger strSimHash;
private int hashbits = 128;
public SimHash(String tokens)
{
this.tokens = tokens;
this.strSimHash = this.simHash();
}
public SimHash(String tokens, int hashbits)
{
this.tokens = tokens;
this.hashbits = hashbits;
this.strSimHash = this.simHash();
}
public BigInteger simHash()
{
int[] v = new int[this.hashbits];
StringTokenizer stringTokens = new StringTokenizer(this.tokens);
while (stringTokens.hasMoreTokens())
{
String temp = stringTokens.nextToken();
BigInteger t = this.hash(temp);
for (int i = 0; i < this.hashbits; i++)
{
BigInteger bitmask = new BigInteger("1").shiftLeft(i);
if (t.and(bitmask).signum() != 0)
{
v[i] += 1;
}
else
{
v[i] -= 1;
}
}
}
BigInteger fingerprint = new BigInteger("0");
for (int i = 0; i < this.hashbits; i++)
{
if (v[i] >= 0)
{
fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i));
}
}
return fingerprint;
}
private BigInteger hash(String source)
{
if (source == null || source.length() == 0)
{
return new BigInteger("0");
}
else
{
char[] sourceArray = source.toCharArray();
BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7);
BigInteger m = new BigInteger("1000003");
BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract(
new BigInteger("1"));
for (char item : sourceArray)
{
BigInteger temp = BigInteger.valueOf((long) item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(source.length())));
if (x.equals(new BigInteger("-1")))
{
x = new BigInteger("-2");
}
return x;
}
}
public int hammingDistance(SimHash other)
{
BigInteger m = new BigInteger("1").shiftLeft(this.hashbits).subtract(
new BigInteger("1"));
BigInteger x = this.strSimHash.xor(other.strSimHash).and(m);
int tot = 0;
while (x.signum() != 0)
{
tot += 1;
x = x.and(x.subtract(new BigInteger("1")));
}
return tot;
}
public static void main(String[] args)
{
String s = "This is a test string for testing";
SimHash hash1 = new SimHash(s, 128);
System.out.println(hash1.strSimHash + " " + hash1.strSimHash.bitLength());
s = "This is a test string for testing also";
SimHash hash2 = new SimHash(s, 128);
System.out.println(hash2.strSimHash + " " + hash2.strSimHash.bitCount());
s = "This is a test string for testing als";
SimHash hash3 = new SimHash(s, 128);
System.out.println(hash3.strSimHash + " " + hash3.strSimHash.bitCount());
System.out.println("============================");
System.out.println(hash1.hammingDistance(hash2));
System.out.println(hash1.hammingDistance(hash3));
}
}
https://github.com/sing1ee/simhash-java
MinHash: http://massivealgorithms.blogspot.com/2014/12/matts-blog-minhash-for-dummies.html