http://en.wikipedia.org/wiki/MinHash
MinHash (or the min-wise independent permutations locality sensitive hashing scheme) is a technique for quickly estimating how similar two sets are.
It's initially used in the AltaVista search engine to detect duplicate web pages and eliminate them from search results.
It has also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words.
Matt's Blog: MinHash for dummies
This is useful when you have a document, and you want to know which other documents to compare to it for similarity.
https://mymagnadata.wordpress.com/2010/12/28/min-hash/
Java code: http://www.sanfoundry.com/java-program-implement-min-hash/
Locality-sensitive hashing (LSH) reduces the dimensionality of high-dimensional data. LSH hashes input items so that similar items map to the same “buckets” with high probability (the number of buckets being much smaller than the universe of possible input items). LSH differs from conventional and cryptographic hash functions because it aims to maximize the probability of a “collision” for similar items.
http://web.stanford.edu/class/cs276b/handouts/minhash.pdf
http://robertheaton.com/2014/05/02/jaccard-similarity-and-minhash-for-winners/
SimHash: http://massivealgorithms.blogspot.com/2014/12/simhash-hash-based-similarity-detection.html
Read full article from Matt's Blog: MinHash for dummies
MinHash (or the min-wise independent permutations locality sensitive hashing scheme) is a technique for quickly estimating how similar two sets are.
It's initially used in the AltaVista search engine to detect duplicate web pages and eliminate them from search results.
It has also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words.
The Jaccard similarity coefficient is a commonly used indicator of the similarity between two sets. For sets A and B it is defined to be the ratio of the number of elements of their intersection and the number of elements of their union:
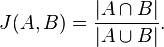
Matt's Blog: MinHash for dummies
A measure of how similar these two sets are is known as the Jaccard Coefficient. It is calculated asnumber of common elements / (total number of elements - number of common elements).
While a document can be though of as a giant set of words, we don't just break down a document into individual words, place them in a set and calculate the similarity, because that looses the importance of the order of the words. The sets
Set a = new Set(["I", "went", "to", "work", "today"]);
Set b = new Set(["today", "I", "went", "to", "work"]);
would be considered 100% similar, even though they clearly are not.
Instead we break a document down into what are known as shingles. Each shingle contains a set number of words, and a document is broken down into total words - single length + 1 number of shingles.
Optimizing the process
So we now have a way to compare two documents for similarity, but it is not an efficient process. To find similar documents to document A in a directory of 10000 documents, we need compare each pair individually. This is obviously not going to scale well.
What we can do to reduce some cycles is compare sets of randomly selected shingles from two documents. So for a document that is 10000 words long, we break it down into 9996 shingles, and randomly select say 200 of those to represent the document.
Computing and saving the random shingle selections
1. Break down the document a set of shingles.
2. Calculate the hash value for every shingle.
3. Store the minimum hash value found in step 2.
4. Repeat steps 2 and 3 with different hash algorithms 199 more times to get a total of 200 min hash values.
Um, 199 more hash algorithms? WTF!
The short answer is that you XOR the value returned by String.hashCode() with 199 random numbers to generate the 199 other hash code values. Just make sure that you are using the same 199 random numbers across all the documents.
Great, but I still have to compare every document to every other document. Can this be optimized?
Locality sensitive hashing (LSH) involves generating a hash code such that similar items will tend to get similar hash codes. This is the opposite of what .hashCode() does.
LSH allows you to precompute a hash code that is then quickly and easily compared to another precomputed LSH hash code to determine if two objects should be compared in more detail or quickly discarded.
This is useful when you have a document, and you want to know which other documents to compare to it for similarity.
https://mymagnadata.wordpress.com/2010/12/28/min-hash/
Lets suppose there are two sets of data S1 {“THIS”,”IS”,”ME”} and S2 {“THAT”,”IS”,”ME”}. Lets create a bit map index for this set of data with rows as union of Set S1 and Set S2 and column values as bits (1,0) representing presence or absence of data row in the set
THIS 1 0
THAT 0 1
IS 1 1
ME 1 1
THAT 0 1
IS 1 1
ME 1 1
Pick n-hash functions (n is random number), n number of hash functions could be any +ve integer >= S1.size()+S2.size(). For this example lets says n = S1.size() + S2.size().
[0][1][2][3][4][5] => {2222,12332,45432,45426,2124,8656}
For each column, hash function keep a slot. With our example we have 2 columns and 6 hash functions
minHashSlots => [0][0] [0][1] [0][2] [0][3] [0][4] [0][5], [1][0] [1][1] [1][2] [1][3] [1][4] [1][5]
Java code: http://www.sanfoundry.com/java-program-implement-min-hash/
public class MinHash<T>
{private int hash[];
private int numHash;
public MinHash(int numHash)
{this.numHash = numHash;
hash = new int[numHash];
Random r = new Random(11);
for (int i = 0; i < numHash; i++)
{int a = (int) r.nextInt();
int b = (int) r.nextInt();
int c = (int) r.nextInt();
int x = hash(a * b * c, a, b, c);
hash[i] = x;
}}public double similarity(Set<T> set1, Set<T> set2)
{int numSets = 2;
Map<T, boolean[]> bitMap = buildBitMap(set1, set2);
int[][] minHashValues = initializeHashBuckets(numSets, numHash);
computeMinHashForSet(set1, 0, minHashValues, bitMap);
computeMinHashForSet(set2, 1, minHashValues, bitMap);
return computeSimilarityFromSignatures(minHashValues, numHash);
}private static int[][] initializeHashBuckets(int numSets,
int numHashFunctions)
{int[][] minHashValues = new int[numSets][numHashFunctions];
for (int i = 0; i < numSets; i++)
{for (int j = 0; j < numHashFunctions; j++)
{minHashValues[i][j] = Integer.MAX_VALUE;
}}return minHashValues;
}private static double computeSimilarityFromSignatures(
int[][] minHashValues, int numHashFunctions)
{int identicalMinHashes = 0;
for (int i = 0; i < numHashFunctions; i++)
{if (minHashValues[0][i] == minHashValues[1][i])
{identicalMinHashes++;}}return (1.0 * identicalMinHashes) / numHashFunctions;
}private static int hash(int x, int a, int b, int c)
{int hashValue = (int) ((a * (x >> 4) + b * x + c) & 131071);
return Math.abs(hashValue);
}private void computeMinHashForSet(Set<T> set, int setIndex,
int[][] minHashValues, Map<T, boolean[]> bitArray)
{int index = 0;
for (T element : bitArray.keySet())
{/** for every element in the bit array*/for (int i = 0; i < numHash; i++)
{/** for every hash*/if (set.contains(element))
{/** if the set contains the element*/int hindex = hash[index];
if (hindex < minHashValues[setIndex][index])
{/** if current hash is smaller than the existing hash in* the slot then replace with the smaller hash value*/minHashValues[setIndex][i] = hindex;
}}}index++;}}public Map<T, boolean[]> buildBitMap(Set<T> set1, Set<T> set2)
{Map<T, boolean[]> bitArray = new HashMap<T, boolean[]>();
for (T t : set1)
{bitArray.put(t, new boolean[] { true, false });
}for (T t : set2)
{if (bitArray.containsKey(t))
{// item is not present in set1bitArray.put(t, new boolean[] { true, true });
}else if (!bitArray.containsKey(t))
{// item is not present in set1bitArray.put(t, new boolean[] { false, true });
}}return bitArray;
}public static void main(String[] args)
{Set<String> set1 = new HashSet<String>();
set1.add("FRANCISCO");
set1.add("MISSION");
set1.add("SAN");
Set<String> set2 = new HashSet<String>();
set2.add("FRANCISCO");
set2.add("MISSION");
set2.add("SAN");
set2.add("USA");
MinHash<String> minHash = new MinHash<String>(set1.size() + set2.size());
System.out.println("Set1 : " + set1);
System.out.println("Set2 : " + set2);
System.out.println("Similarity between two sets: "
+ minHash.similarity(set1, set2));
}}
Locality-sensitive hashing (LSH) reduces the dimensionality of high-dimensional data. LSH hashes input items so that similar items map to the same “buckets” with high probability (the number of buckets being much smaller than the universe of possible input items). LSH differs from conventional and cryptographic hash functions because it aims to maximize the probability of a “collision” for similar items.
http://web.stanford.edu/class/cs276b/handouts/minhash.pdf
http://robertheaton.com/2014/05/02/jaccard-similarity-and-minhash-for-winners/
SimHash: http://massivealgorithms.blogspot.com/2014/12/simhash-hash-based-similarity-detection.html
Read full article from Matt's Blog: MinHash for dummies