Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the following operations: getand set.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. set(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted.
Follow up:
Could you do both operations in O(1) time complexity?
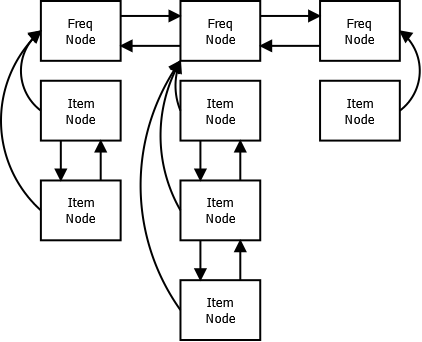
https://discuss.leetcode.com/topic/69137/java-o-1-accept-solution-using-hashmap-doublelinkedlist-and-linkedhashset Two HashMaps are used, one to store <key, value> pair, another store the <key, node>. I use double linked list to keep the frequent of each key. In each double linked list node, keys with the same count are saved using java built in LinkedHashSet. This can keep the order. Every time, one key is referenced, first find the current node corresponding to the key, If the following node exist and the frequent is larger by one, add key to the keys of the following node, else create a new node and add it following the current node. All operations are guaranteed to be O(1).
publicclassLFUCache {
private Node head = null;
privateint cap = 0;
private HashMap<Integer, Integer> valueHash = null;
private HashMap<Integer, Node> nodeHash = null;
publicLFUCache(int capacity) {
this.cap = capacity;
valueHash = new HashMap<Integer, Integer>();
nodeHash = new HashMap<Integer, Node>();
}
publicintget(int key) {
if (valueHash.containsKey(key)) {
increaseCount(key);
return valueHash.get(key);
}
return-1;
}
publicvoidset(int key, intvalue) {
if ( cap == 0 ) return;
if (valueHash.containsKey(key)) {
valueHash.put(key, value);
} else {
if (valueHash.size() < cap) {
valueHash.put(key, value);
} else {
removeOld();
valueHash.put(key, value);
}
addToHead(key);
}
increaseCount(key);
}
privatevoidaddToHead(int key) {
if (head == null) {
head = new Node(0);
head.keys.add(key);
} elseif (head.count > 0) {
Node node = new Node(0);
node.keys.add(key);
node.next = head;
head.prev = node;
head = node;
} else {
head.keys.add(key);
}
nodeHash.put(key, head);
}
privatevoidincreaseCount(int key) {
Node node = nodeHash.get(key);
node.keys.remove(key);
if (node.next == null) {
node.next = new Node(node.count+1);
node.next.prev = node;
node.next.keys.add(key);
} elseif (node.next.count == node.count+1) {
node.next.keys.add(key);
} else {
Node tmp = new Node(node.count+1);
tmp.keys.add(key);
tmp.prev = node;
tmp.next = node.next;
node.next.prev = tmp;
node.next = tmp;
}
nodeHash.put(key, node.next);
if (node.keys.size() == 0) remove(node);
}
privatevoidremoveOld() {
if (head == null) return;
int old = 0;
for (int n: head.keys) {
old = n;
break;
}
head.keys.remove(old);
if (head.keys.size() == 0) remove(head);
nodeHash.remove(old);
valueHash.remove(old);
}
privatevoidremove(Node node) {
if (node.prev == null) {
head = node.next;
} else {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
}
classNode {
publicint count = 0;
public LinkedHashSet<Integer> keys = null;
public Node prev = null, next = null;
publicNode(int count) {
this.count = count;
keys = new LinkedHashSet<Integer>();
prev = next = null;
}
}
}
To put and get data in Java in O(1), We need to use Map or more specifically HashMap.
HashMap<K,V>
Since we need to find the least frequently used item to remove it for putting new data, we need a counter to keep track number of times a Key(K) has been accessed. Access could be get or put. To achieve that we need another Map<K,C>;K is the key of the item to put and C is the counter.
HashMap<K,C>
From the above two data structure, we can put and get data in O(1). We can also get the counter of an item has been used.
Another thing, we need, is a list where we can store the information of count and items key. Lets elaborate that in details, assume A has been used 5times, B also has been used 5times. We need to store that information such a ways that will hold the items in a list based on their insertion order. (FIFO). To achieve that we can use HashSet<K> and more precisely LinkedHashSet<K>. But we want to keep track of the counter as well(in our example 5 times or 5). So we need another map.
HashMap<K,LinkedHashSet<K>>
We need a tag or min variable, it will hold the current min. Whenever a new Item insert into the cache min=1; It will be increased only when there is no items in the (counter==min).
We need to implement get() and set() in average O(logn) time, or we will get TLE.
Obviously, we need a hashmap to remember key-value pair.
What we need to do, is to remember (frequency, recentness) for each key; and sort them to get the smallest one.
So, we need to use Collection such as TreeSet or PriorityQueue.
Now, the only question is, how to update?
It is difficult to update (frequency, recentness) in the collection, as we don't know the index.
(Maybe using binary search or hashmap can do this, I haven't tried it.)
The trick is, just override equals() and hashCode() function, in order to use remove.
How do we implement evict method? When size of map reaches max capacity, we need to find item with lowest frequency count. There are 2 problems:
We have to iterate through all values of frequencies map, find lowest count and remove corresponding key from both maps. This will take O(n) time.
Also, what if there are multiple keys with same frequency count? How do we find least recently used? That’s not possible because HashMap does not store the order of insertion.
To solve both of above problems we need to add one more data structure: Sorted map with frequency as map-keys and ‘list of item-keys with same frequency’ as map-values.
We can add new item can to the end of the list with frequency 1.
We can find the list with lowest frequency in O(1), since map is sorted by frequencies.
We can delete the first item of the list (of lowest frequency) since that will be least recently used. Also O(1).
publicclassLFUCache{privateMap<Integer,Integer>values=newHashMap<>();privateMap<Integer,Integer>counts=newHashMap<>();privateTreeMap<Integer,List<Integer>>frequencies=newTreeMap<>();privatefinalintMAX_CAPACITY;publicLFUCache(intcapacity){MAX_CAPACITY=capacity;}publicintget(intkey){if(!values.containsKey(key)){return-1;}// Move item from one frequency list to next. Not O(1) due to list iteration.intfrequency=counts.get(key);frequencies.get(frequency).remove(newInteger(key)); //O(n)if(frequencies.get(frequency).size()==0){frequencies.remove(frequency);// remove from map if list is empty}frequencies.computeIfAbsent(frequency+1,k->newLinkedList<>()).add(key);counts.put(key,frequency+1);returnvalues.get(key);}publicvoidset(intkey,intvalue){if(!values.containsKey(key)){if(values.size()==MAX_CAPACITY){// first item from 'list of smallest frequency'intlowestCount=frequencies.firstKey();intkeyToDelete=frequencies.get(lowestCount).remove(0);if(frequencies.get(lowestCount).size()==0){frequencies.remove(lowestCount);// remove from map if list is empty}values.remove(keyToDelete);counts.remove(keyToDelete);}values.put(key,value);counts.put(key,1);frequencies.computeIfAbsent(1,k->newLinkedList<>()).add(key);// starting frequency = 1}}}
While solving our delete problem, we accidentally increased our access operation time to O(n). How? Note that all of item-keys sharing same frequency are in a list. Now if one of these items is accessed, how do we move it to list of next frequency? We will have to iterate through the list first to find the item, which in worst-case will take O(n) operations.
To solve the problem, we somehow need to jump directly to that item in the list without iteration. If we can do that, it will be easier to delete the item and add it to end of next frequency list.
Unfortunately, this is not possible using our in-built data structures. We need to create a new one (mentioned in the paper).
We need to store each item’s position.
We will create a simple class which stores item’s key, value and its position in the list.
We will convert the linked list to
We need to store each item’s position.
We will create a simple class which stores item’s key, value and its position in the list.
We will convert the linked list to
publicclassLFUCache{privateMap<Integer,Node>values=newHashMap<>();privateMap<Integer,Integer>counts=newHashMap<>();privateTreeMap<Integer,DoubleLinkedList>frequencies=newTreeMap<>();privatefinalintMAX_CAPACITY;publicLFUCache(intcapacity){MAX_CAPACITY=capacity;}publicintget(intkey){if(!values.containsKey(key)){return-1;}Nodenode=values.get(key);// Move item from one frequency list to next. O(1) this time.intfrequency=counts.get(key);frequencies.get(frequency).remove(node);removeIfListEmpty(frequency);frequencies.computeIfAbsent(frequency+1,k->newDoubleLinkedList()).add(node);counts.put(key,frequency+1);returnvalues.get(key).value;}publicvoidset(intkey,intvalue){if(!values.containsKey(key)){Nodenode=newNode(key,value);if(values.size()==MAX_CAPACITY){intlowestCount=frequencies.firstKey();// smallest frequencyNodenodeTodelete=frequencies.get(lowestCount).head();// first item (LRU)frequencies.get(lowestCount).remove(nodeTodelete);intkeyToDelete=nodeTodelete.key();removeIfListEmpty(lowestCount);values.remove(keyToDelete);counts.remove(keyToDelete);}values.put(key,node);counts.put(key,1);frequencies.computeIfAbsent(1,k->newDoubleLinkedList()).add(node);// starting frequency = 1}}privatevoidremoveIfListEmpty(intfrequency){if(frequencies.get(frequency).size()==0){frequencies.remove(frequency);// remove from map if list is empty}}privateclassNode{privateintkey;privateintvalue;privateNodenext;privateNodeprev;publicNode(intkey,intvalue){this.key=key;this.value=value;}publicintkey(){returnkey;}publicintvalue(){returnvalue;}}privateclassDoubleLinkedList{privateintn;privateNodehead;privateNodetail;publicvoidadd(Nodenode){if(head==null){head=node;}else{tail.next=node;node.prev=tail;}tail=node;n++;}publicvoidremove(Nodenode){if(node.next==null)tail=node.prev;elsenode.next.prev=node.prev;if(head.key==node.key)head=node.next;elsenode.prev.next=node.next;n--;}publicNodehead(){returnhead;}publicintsize(){returnn;}}}
Step 4: Remove the counts HashMap
Note that we need the intermediate map called counts to jump to the appropriate list. We can go one step further (code not written) to remove this extra data structure.
Convert frequencies HashMap keys into a doubly linked list
Add variable reference to each item, which points to corresponding frequency
So instead of counts hashmap, we can go get frequency node directly from the item itself.
This is precisely the algorithm implemented in this paper